Redshift
Redshift MS SQL
MS SQL  MySQL
MySQL PostgreSQL
PostgreSQL Trino
Trino Starburst
Starburst All resources
All resources Talk to sales
Talk to sales BLOG
Powering faster, smarter AI outcomes with Gathr.ai and NVIDIA RAPIDS
Summary
Although AI models are trained and deployed on GPUs, the data feeding them is often processed on CPU-based systems—causing performance bottlenecks and higher costs. Gathr.ai’s integration with NVIDIA RAPIDS bridges this gap by bringing together data processing and AI workflows on a shared GPU-accelerated infrastructure. The result: better performance, higher ROI on infrastructure, scalable workloads, and faster time to insights.
As organizations are looking to scale their AI initiatives, one roadblock keeps surfacing: data pipelines aren’t keeping up. While AI models are being trained and deployed on GPUs, the data that feeds them is still prepared in CPU-based systems — leading to performance gaps, resource underutilization, and increased costs. This disconnect not only slows down AI development cycles, but also impacts ROI on infrastructure investments.
To move faster and scale smarter, businesses need a unified approach that brings data engineering and AI together on the same GPU-accelerated foundation. This blog explores how the integration of Gathr.ai with NVIDIA RAPIDS delivers just that — simplifying complex data workflows, maximizing GPU utilization, and enabling teams to build, operationalize, and scale high-performance data and AI products for real-world use cases.
Supercharging data and AI workflows with Gathr.ai + NVIDIA RAPIDS
NVIDIA RAPIDS is a suite of open-source software libraries and APIs designed to accelerate data processing and machine learning workflows using GPUs. By harnessing the parallel computing power of NVIDIA’s GPU hardware, RAPIDS speeds up common data and AI tasks like data wrangling, transformation, model training, and inference. This enables quicker model iterations, faster time-to-insights, and substantial cost savings.
Gathr.ai is now integrated with NVIDIA RAPIDS, bringing together data processing and AI workflows on a shared GPU-accelerated infrastructure. By combining Gathr.ai’s advanced data+AI pipelining capabilities with RAPIDS’ GPU-powered acceleration, teams can process large datasets faster and handle complex workflows effortlessly. They can speed up both data preparation and model training, empowering businesses to make faster, smarter decisions, and maintain a competitive edge. What’s more, Gathr.ai empowers developers with complete flexibility and control at every step. With the integration of RAPIDS, they can harness the power of GPUs without changing their existing workflows. Here’s what the Gathr.ai + RAPIDS integration enables:
- Faster performance, lower latency: Leverage GPU-powered data processing for faster execution, near-real-time workflows, and seamless experimentation.
- Higher ROI on GPU infrastructure: Maximize utilization of GPU resources across both data and AI workloads for better price-performance.
- Seamless GPU adoption: Easily transition existing pipelines to run on RAPIDS-powered clusters — no ETL rewrites or new tooling required.
- Flexible workload management: Choose which workloads to run on GPUs and which ones to execute on CPUs, optimizing cost and compute efficiency.
- Scalable and cost-efficient infrastructure: Seamlessly allocate additional GPU resources during peak workloads, while utilizing fixed clusters for routine operations, with on-demand scalability.
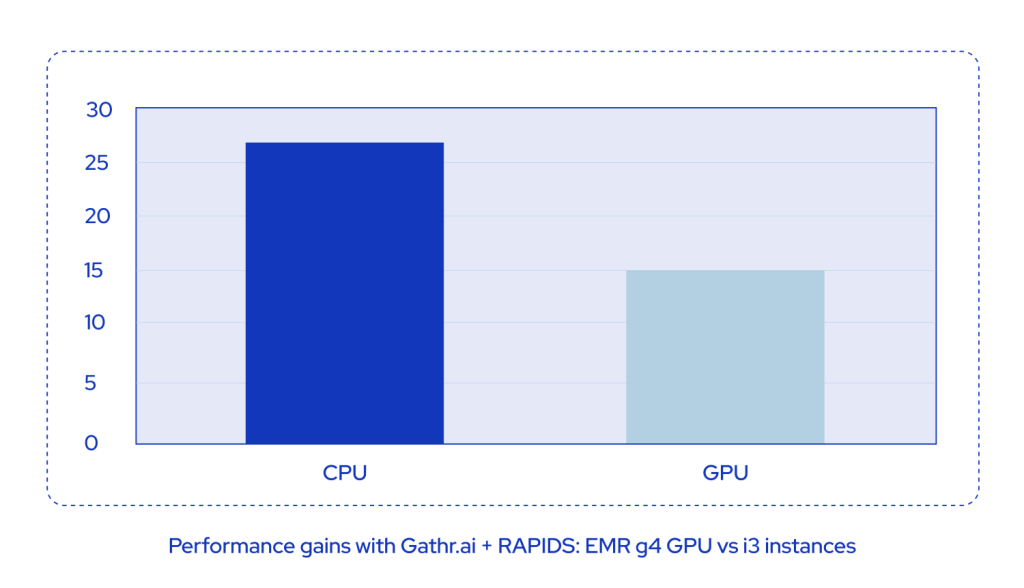
Case in point: Benchmarking NVIDIA GPU-accelerated processing
To highlight the improvements that GPU acceleration brings to data pipeline workflows, we benchmarked the performance of data processing with and without NVIDIA RAPIDS. We used TPC-DS queries to benchmark processing results and compare query performance on CPU-only systems vs. GPU-accelerated systems on Amazon EMR clusters.
In such read-intensive jobs, where most of the execution time is spent simply reading data rather than processing it, the benefits of GPU acceleration are limited. Yet, we noticed a notable increase in data access throughput compared to CPU-only systems.
We observed up to 2x performance gains when running the queries on Amazon EMR, along with significantly lower operational costs.
Putting Gathr.ai + RAPIDS to work in the real world
Whether you’re processing massive datasets or enabling downstream AI workflows, Gathr.ai + RAPIDS power high performance, real-world data and AI applications across industries. Here are a few of the top use cases:
- Patient journey modeling in healthcare: Process and join millions of patient records from Electronic Health Records (EHRs), labs, and billing systems to build longitudinal patient journeys. RAPIDS speeds up filtering, deduplication, and complex joins, while Gathr.ai simplifies orchestration — enabling faster cohort identification for clinical studies or AI-driven diagnostics.
- Customer 360 and personalization in retail: Unify clickstream data, transaction history, and product catalogs to create dynamic customer profiles. RAPIDS accelerates transformation and feature generation, while Gathr.ai routes outputs into real-time recommendation engines/marketing segmentation models — all without CPU bottlenecks.
- Financial fraud detection: Ingest and transform transactional data in near real-time using GPU-accelerated feature extraction. Reduce fraud detection latency from minutes to seconds with faster scoring and labeling using downstream AI models.
- Logistics optimization and delivery forecasting: Aggregate location data, inventory updates, and delivery status feeds from IoT devices across global fleets. Enable faster route recalculations, anomaly detection, and predictive ETA modeling, for better operational efficiency in high-frequency logistics environments.
- Real-time sentiment analysis from multilingual social data: Stream social media feeds, enrich them with metadata (language, topic, region), and perform NLP-based sentiment scoring. RAPIDS accelerates pre-processing and vectorization, while Gathr.ai handles pipeline management and model integration for marketing or crisis management teams.
Conclusion
The integration of Gathr.ai with NVIDIA RAPIDS provides a unified, future-proof approach to solving data challenges in the AI era. With GPU-accelerated infrastructure, organizations can tackle vast datasets more efficiently, reduce operational costs, and generate intelligence faster — crucial advantages in today’s data-driven landscape. Adopting this unified solution empowers businesses to skyrocket performance and AI innovation.
To learn more about how Gathr.ai and NVIDIA RAPIDS can supercharge your data engineering, AI and analytics workflows, schedule a demo today!

Table of Contents
Data Warehouse
Intelligence
Unlock intelligence driven by complete data context